A Hybrid Recommender with Yelp Challenge Data -- Part II
Introduction:
As we explored the different approaches of building and implementing our pipeline, a few factors were taken into consideration:
1. Can it be built in two weeks?
With two weeks to complete our capstone and having little data engineering experience, we divided the project into three phases:
- Researching what's necessary to build a pipeline
- Implementing a working pipeline
- Optimizing our pipeline
2. Can we each work on our parts of the Capstone without impacting each other?
Being a team of five, we had to be intentional about how we distributed and then integrated the individual pieces that made up our project.
3. Are we using the appropriate technology and is it scalable?
With the popularity of "big data" in the tech-world, we wanted to make sure we were using the appropriate tools for our project. Additionally, our project needed to be scalable. Amazon Web Services (AWS) offered the flexibility to allocate the appropriate number of resources, allowing you to upgrade/downgrade your configuration based on computational needs.
The Components:
Our pipeline consisted of three main parts:
- Apache Spark - a fast and general engine for large-scale data processing: This is where our machine-learning models were trained and data was processed.
- Flask - a microframework for Python: Our front-end web application.
- Apache Kafka - a distributed streaming platform: The connection between our front-end (Flask) and our models in Spark.
Having the least familiarity with Kafka and Spark, we began with those two components and integrated our Flask App once we had succesffully implemented a connection between Kafka and Spark.
Building & Configuring the Pipeline:
Google (Cloud), Amazon (AWS), and Microsoft (Azure) all offer free trials for their cloud computing services, providing a nice option for students to gain familiarity with the world of web services. For our project, we decided to use Amazon Web Services.
Both Spark & Kafka will be installed on Amazon EC2 Instances.
Configuring Kafka on EC2:
As touched on above, we used Kafka to stream information from our webapp into our machine-learning model and then send new information back to our webapp. If you'd like more information on Kafka, they provide a nice introduction with more details on its API and various configurations.
Step 1: Creating an EC2 Instance:
- Log into your AWS dashboard.
- From your AWS dashboard, click on the launch a virtual machine wizard to create a new instance (this will be where you will run Kafka/Spark on). We used a t2.medium type on an Ubuntu Server, though a t2.micro instance-type can also be used.
- Make sure you download the key-pair .pem file, as you will need it to log into the instance from your local machine. If you're using a Mac/Linux machine, you can store your SSH keys in the ~/.ssh/ directory. Windows users, click here to configure your ssh key to work with Putty. To make your key executable on your local machine, change its permissions by running:
$ chmod 600 ~/.ssh/keyname.pem
You'll need the following information to log into your EC2 instance:
Public DNS (IPv4): ec2-41-351-341-121.compute-1.amazonaws.com
IPv4 Public IP: 41.351.341.121
SSH Username: ubuntu (default)
SSH-key: keyname.pem
4. Once your EC2 instance is up and running, you can connect to it by executing the following command in your shell client:
"ssh -i "location of pem key" server_username@public_dns_address"
$ ssh -i "~/.ssh/keyname.pem" ubuntu@ec2-xx-xxx-xxx-xxx.compute-1.amazonaws.com
5. AWS configures your EC2 instance to only be accessable via SSH and on your current IP Address. If you need access from another IP Address, you can do so by changing the allowed IP's in your Security Group settings in AWS.
Step 2: Installing Java:
Once you have connected to your ec2 instance, run the following commands to update the packages library and update all installed packages:
$ sudo apt-get update
$ sudo apt-get upgrade
Kafka runs on top of the *Java Runtime Environment*, which must be installed first:
$ sudo apt-get install default-jdk
To confirm installation, you should see the following after running java -version:
ubuntu@ip-xxx-xx-xx-xxx:~/xxx_x.x-x.xx.x.x$ java -version
openjdk version <span style="color: #0000ff;">"1.8.0_131"</span>
OpenJDK Runtime Environment (build 1.8.0_131-8u131-b11-0ubuntu1.16.04.2-b11)
OpenJDK 64-Bit Server VM (build 25.131-b11, mixed mode)
Step 3: Installing Kafka:
Download the latest version of Kafka and un-tar the compressed file. Once you have extracted the file, you can delete the .tgz file you downloaded and enter your new Kafka directory:
$ wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.2.0/kafka_2.11-0.10.2.0.tgz
$ tar -xzf kafka_2.11-0.10.2.0.tgz
$ rm kafka_2.11-0.10.2.0.tgz
$ cd kafka_2.11-0.10.2.0/
Step 4: Configuring Kafka:
Kafka is comprised of the following components:
- ZooKeeper: Apache server configuration service that Kafka runs on.
- Kafka Server: The Kafka server that streams will be streamed through.
- Topics: Topics can be thought of as channels where data can travel through. A server can have multiple topics and each topic can have multiple subscribers.
- Producers: Produces data to the specified topic.
- Consumers: Consumes data from the specified topic.
If you are running a t2.micro EC2 instance, you will need to reconfigure your ZooKeeper and Kafka server script to prevent your instance from running out of memory. Use your preferred editor to update the .sh file and replace the memory size to 256MB.
$ vim bin/zookeeper-server-start.sh
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"
fi
$ vim bin/kafka-server-start.sh
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms256M"
fi
On your screen, launch a ZooKeeper server (note: you must be in Kafka's home directory). The ZooKeeper acts as the server.
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Step 5: Launch ZooKeeper & Kafka Server:
Launch a new screen. Screen lets you to have multiple "screens" running at once, allowing you to run .sh files on their own unique screen.
$ screen
In your new screen, launch a ZooKeeper Server:
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Exit out of the screen by typing ctrl+a and then d. This keeps your server running and to continue working on your instance.
Enter a second screen and launch a Kakfa Server:
$ bin/kafka-server-start.sh config/server.properties
Again, exit out of the screen by typing ctrl+a and then d. The default ports for your ZooKeeper & Kafka server are 2181 & 9092, respectively (additional Kafka servers use ports 9093, 9094, ...).
Step 6: Create a Kafka Topic:
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic1
We should now see the topic we just created by running the list topic command:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181 topic1
Configuring Spark on EC2:
To configure Spark on an EC2 instance, we followed this step-by-step guide.
Spark Structured Streaming:
To read our Kafka streams into Spark, we used Spark's Structured Streaming platform.
Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
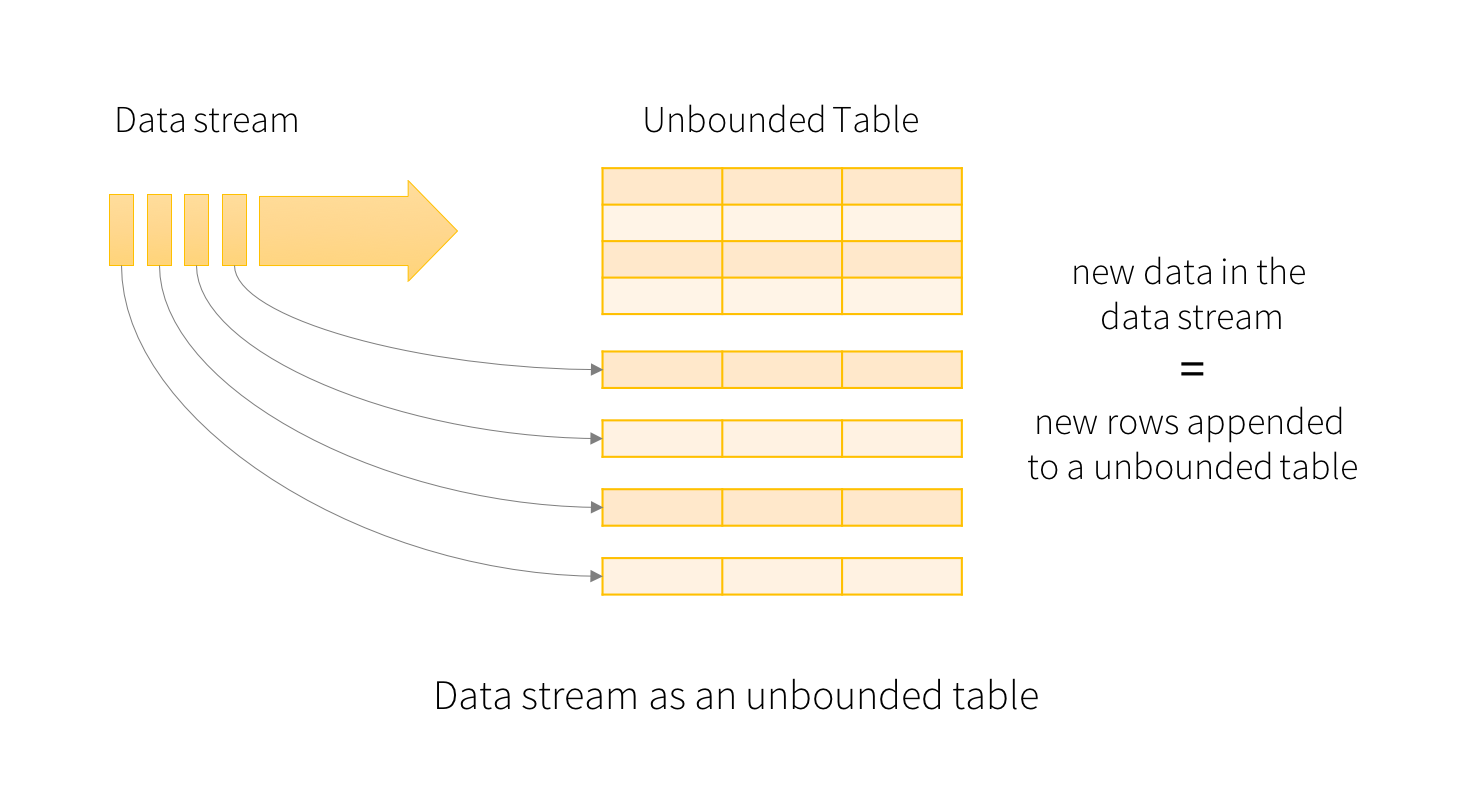
Structured Streaming simplifies the syntax for reading and writing streams, replacing read() & write() with readStream() & writeStream(). Each new line of data being streamed into Spark can be thought of as an appended observation to an unbounded table, as visualized above.
On your Spark EC2 instance, create a python script with the following code:
This script will be used to test the communication between Spark, Kafka, and your local machine, confirming that all three components can communicate with each other.
Testing the Pipeline:
To test our pipeline, we wrote a simple Python script to send a new observation to our Kafka server every two seconds:
The video below shows each of the three sections of our pipeline in communication. The top-right corner is the Python code above, running on our local machine. The middle section is a Kafka consumer, showing each stream being consumed by Kafka. The bottom section is the Spark console, showing Spark reading in each observation and writing it out to the console.
The skills the authors demonstrated here can be learned through taking Data Science with Machine Learning bootcamp with NYC Data Science Academy.